Karteikarte Daten #
Karteikarten #
Der Berichts-Designer hat verschiedene Ansichten, die in Karteikarten unterteilt sind. Sie können jederzeit zwischen den Ansichten „Daten“, „Berechnungen“, „Entwurf“ und „Vorschau“ wechseln. An dieser Stelle erhalten Sie einen kurzen Überblick; die genaue Beschreibung zu den einzelnen Karteikarten finden Sie in den anschließenden Kapiteln.
Karteikarte Daten #
Jeder Ausdruck benötigt Daten zum Ausdrucken. Die Zusammenstellung, Sortierung, Feldauswahl und Verkettung der Daten wird Datenquelle genannt.
Diese eingebetteten Datenquellen können bei neuen Berichtsvorlagen und bei den meisten Berichtsvorlagen bequem im Berichts-Designer angelegt bzw. verändert werden. Den Berichts-Designer erreichen Sie über die Schnellstartleiste über den Modulpunkt Berichts-Designer.
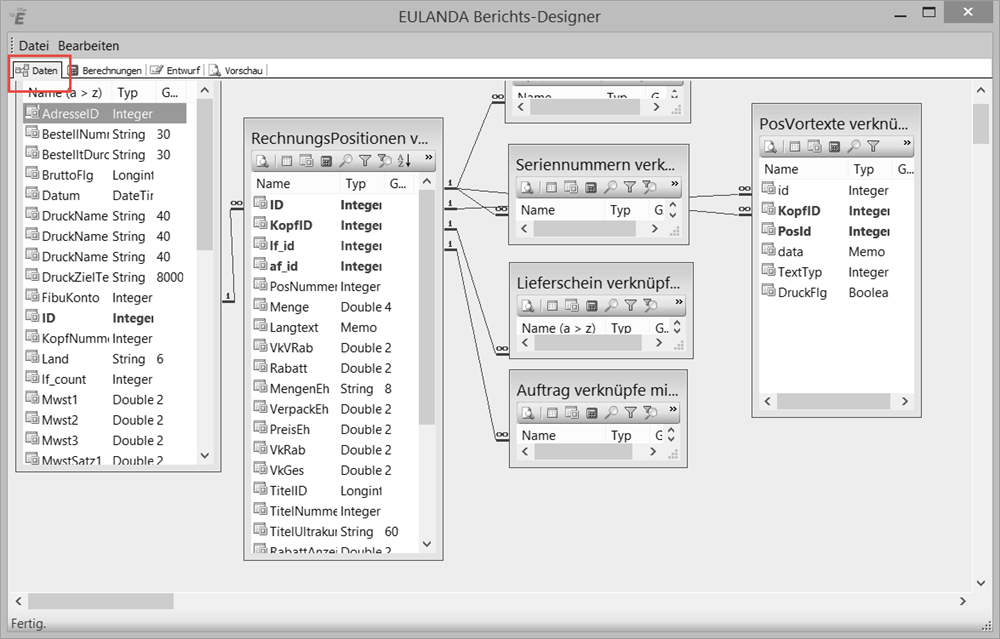
Karteikarte - Daten
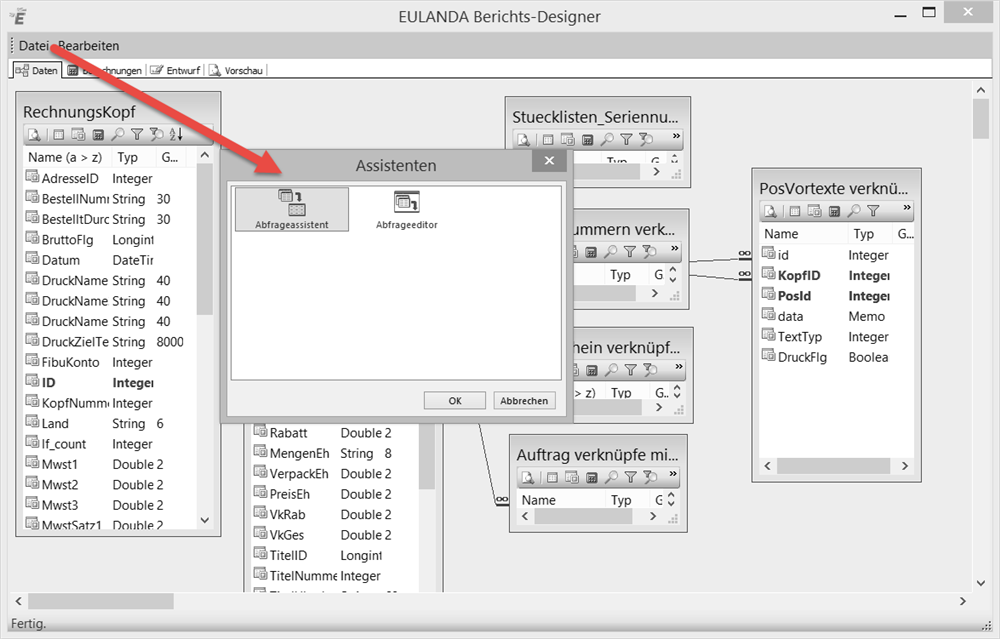
Datenquelle über den Assistenten anlegen #
Nach Wechsel auf die Karteikarte „Daten“ kann der Abfrageassistent im Menü „Daten“ unter dem Punkt „Neu“ aufgerufen werden.
Der Abfrageassistent führt Sie durch die Tabellen- und Feldauswahl. Sie können im Assistenten neue Feldwerte berechnen lassen, Daten gruppieren, Daten sortieren lassen und Filterbedingungen setzen.
Assistent öffnen
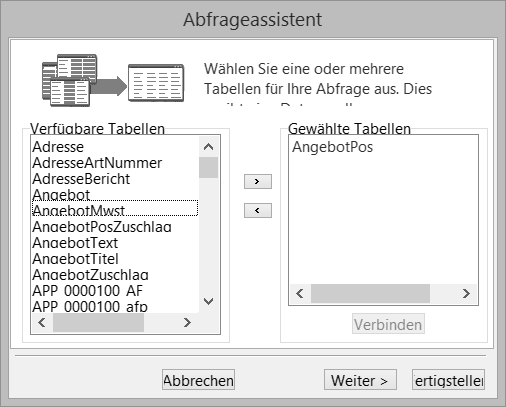
Tabelle oder Sicht auswählen #
Der Abfrageassistent beginnt mit der Auswahl der Tabellen und Sichtauswahl.
Auswahl
Die Übernahme der Tabelle bzw. Sicht erfolgt durch Doppelklick oder durch Auswahl und Betätigen des Pfeil „rechts“ zwischen den beiden Boxen. In der Regel wird man nur eine Datenquelle auswählen.
Sollen alle Felder der Tabelle ausgewählt werden, und möchten Sie auf einen Filter oder eine Sortierung verzichten, so können Sie bereits die Datenquelle fertigstellen.
Welche Tabelle wird wofür benutzt? #
Namen, die ein Leerzeichen bzw. einen Unterstrich enthalten sind Sichten, alle anderen Namen sind Tabellen. Sichten werden verwendet, um für einen bestimmten Zweck optimierte Zusammenstellungen von Feldern zu erhalten. Während Tabellen nur die Felder enthalten, die auch wirklich gespeichert sind, können Sichten neben solchen Feldern auch berechnete Felder enthalten, z.B. den Monatsnamen für ein Rechnungsdatum. Sichten erlauben es auch, Feldwerte aus anderen Tabellen mit zu verwenden.
Sichten, die mit „Print“ beginnen, wurde speziell für den Druck optimiert. Diese enthalten sehr viele berechnete Felder. Bei Anschriften stehen beispielsweise Variablen mit den Namen Druckname1,2,3 neben den üblichen Tabellenfeldnamen Name1,2,3 zur Verfügung. Diese Drucknamen speichern die Namenszeilen so um, dass ggf. enthaltene Leerzeilen am Anfang der Zeilen stehen. Rechnungen enthalten über Drucksichten (=Printsichten oder Printviews), unabhängig von Rechnung oder Gutschrift, stets positive Beträge.
Sichten mit „Master“ im Namen sind komplexe Sichten, die über viele berechnete Felder verfügen.
Für Statistiken, die auf Kreuztabellen basieren, gibt es Sichten mit dem Namen „Pivot“. Diese optimieren alle gruppierbaren Berechnungen.
In der Onlinehilfe finden Sie in einem eigenen Handbuch mit dem Titel „Microsoft SQL-Server“ ein Kapitel mit der Bezeichnung „Feldbeschreibungen“. Dort finden Sie auch weiterführende Informationen zu den Tabellen- und Sichten-Namen.
Eine zweite Tabelle hinzufügen #
Werden ausnahmsweise mehrere Tabellen benötigt, so werden diese auf der linken Seite angewählt. Über einen Zusatz-Dialog wird eine Gemeinsamkeit abgefragt, die beide Tabellen sinnvoll miteinander verbindet. Beide Tabellen werden nach der Zusammenführung als eine Datenquelle dargestellt. Dies ist zum Beispiel sinnvoll, wenn man zu den Adressdaten auch die Vertreterdaten in einer einzigen Datenquelle benutzen möchte.
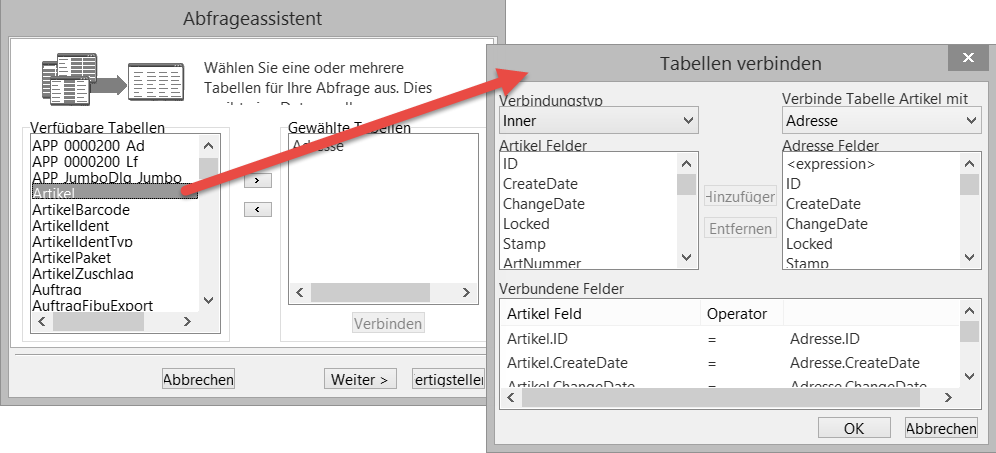
Tabellen verbinden
Wird die zweite Datenquelle ausgewählt, so schlägt der Assistent für die Gemeinsamkeit eine Reihe von Verbindungen vor. Diese werden im unteren Bereich eingeblendet. Sie sind wie vorgeschlagen nicht verwendbar. Aus diesem Grund werden diese unteren Einträge markiert und über die Schaltfläche „Entfernen“ gelöscht. Benötigt wird eine einzige Verbindung und zwar von der ID der zweiten Tabelle – hier Vertreter – zur VertreterID der Adresse.
Der Verbindungstyp wird hierbei auf „Left Outer“ eingestellt. Das bedeutet, dass auch Daten geladen werden, zu denen es keinen Vertreter gibt. Würde man den Standard „Inner“ benützen, so würden nur Adressen geladen, zu denen es in jedem Fall einen Vertreter gibt.
Technische Information #
EULANDA® unterstützt Verbindungen zu den Tabellen untereinander über ID’s. Hierbei hat jede Tabelle eine eigene ID, dies kann man vereinfacht als Speicherplatz des Datensatzes bezeichnen. Hängt eine Tabelle logisch von einer anderen ab, so wird eine ID mit Namen der abhängigen Tabelle als „Verbindungs-ID“ benutzt. In Adressen wird beispielsweise ein Vertreter unterstützt. Die VertreterID zeigt damit auf die ID der Vertretertabelle; bei Rechnungen zeigt die KopfID der Position auf die ID des Kopfdatensatzes und die AdresseID zeigt auf die ID der zum Kopfdatensatz zugehörigen Adresse.
Alle Tabellen sind auf diese Weise in einem Netzwerk von Abhängigkeiten verbunden. Durch diese einfache Logik können nun jederzeit Zusatzinformationen „nachgeladen“ werden, indem man eine Datenquelle mit zwei oder mehr Tabellen definiert und die Abhängigkeit angibt.
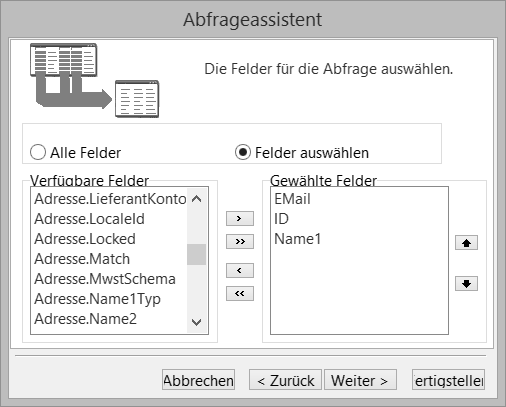
Felder auswählen #
Im nächsten Dialog des Assistenten können Sie bestimmen, ob alle Felder der neuen Datenquelle verwendet werden sollen, oder ob Sie eine Auswahl von bestimmten Feldern vornehmen möchten.
Felder wählen
Wenn Sie viele Datensätze gespeichert haben, ist es immer sinnvoll, nur die wirklich benötigten Felder auszuwählen. Dies minimiert den Arbeitsspeicherbereich enorm – und was sicherlich ebenso wichtig ist – die Operation kann schneller ausgeführt werden.
Die Felder können per Doppelklick oder durch Anwählen und Betätigen des Pfeils „rechts“ zwischen den beiden Boxen angefügt werden. Die Reihenfolge der Felder kann für die Datenquelle auch im Nachhinein geändert werden. Hierzu sind die Pfeile auf/ab rechts außen vorhanden.
Wurden mehrere Tabellen ausgewählt und die Feldnamen sind identisch, wie zum Beispiel beim Match, den gibt es bei Adressen und Vertretern, so können Sie sich am Namen der Tabelle orientieren.
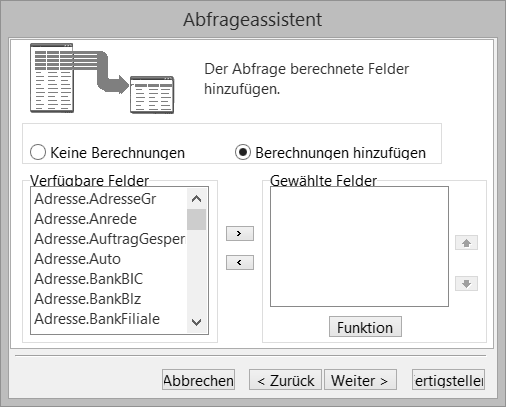
Berechnungen hinzufügen #
Über den Berechnungen-Dialog des Abfrageassistenten können Sie neue Felder, wie z.B. Summen, berechnen lassen. Berechnungen sind nur dann sinnvoll, wenn die Datensätze gruppiert werden. Die Summe des Saldos einer einzigen Adresse ergäbe keinen Sinn. Die Summe über alle Adressen bestimmter Länder aber schon eher.
Berechnung
Die Entscheidung, ob Berechnungen durchgeführt werden sollen oder nicht, erfolgt in einer Vorauswahl.
Wenn Sie sich in der Vorauswahl für Berechnungen entschieden haben, können Sie nun links das Feld auswählen mit dem die Berechnungen durchgeführt werden.
Nach Auswahl des Feldes wird über den Zusatzdialog die Art der Berechnung eingestellt.
Hier haben Sie die Möglichkeit, neben Summen auch Anzahl, Durchschnitt, Minimal- oder den Maximalwert einzustellen.
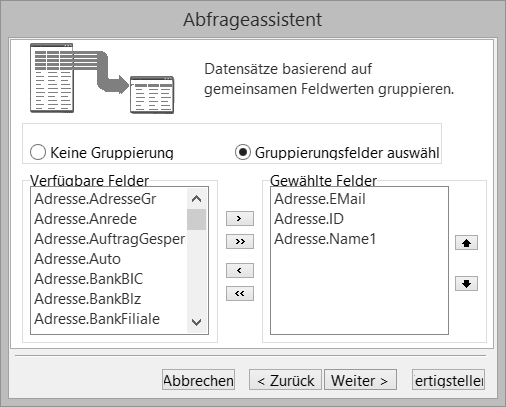
Gruppen definieren #
Im nächsten Dialog können Sie die Gruppierungsfelder auswählen. Wurde zuvor eine Berechnung ausgewählt, so werden automatisch alle Felder der Feldauswahl in die Gruppenliste eingetragen.
Gruppierungen
Sie dürfen in die Gruppe zwar weitere Felder aufnehmen, jedoch müssen mindestens die Felder der Feldliste enthalten sein.
Die zuvor eingestellte Berechnung wird für alle Gruppenfelder durchgeführt. Hierbei werden alle gleichen Feldinhalte laut der Berechnung zusammengefasst. In diesem Beispiel also der Matchcode und der Ort. Für alle gleichen Orte und für alle gleichen Matchcodes wird dementsprechend eine Summe gebildet. Insgesamt werden nur die Kombinationen der Feldwerte vom SQL-Server abgerufen.
Gruppenbildungen im SQL-Server sind vornehmlich für Kurzstatistiken und Übersichten geeignet.
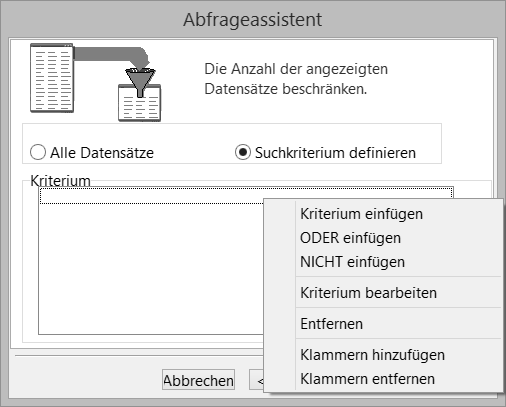
Filterbedingung setzen #
Möchte man nicht alle Daten vom SQL-Server abrufen, so lassen sich über Filterbedingungen Einschränkungen setzen.
Filter setzen
Haben Sie sich dafür entschieden, nicht alle Daten abzurufen, so können Sie im nächsten Dialog die Einschränkungen definieren.
Über das rechte Mausmenü können Sie im weißen Teil der Filterbox die Kriterien, also die Bedingungen, einfügen.
Im Kriteriendialog wählen Sie aus, ob ein Feldwert kleiner, größer, gleich sein oder eine andere Bedingung erfüllen muss. Sie können auf diese Weise beliebig viele Kriterien in die Auswahl einfügen. Neben der Kriterienauswahl hat das Rechte-Mausmenü auch die Option, Klammern zu setzen und logische Operatoren wie UND und ODER zu verwenden.
Es ist nicht erforderlich, dass das Feld, das eine Bedingung erfüllen muss, auch in der Datenquelle vorhanden ist. Die Bedingung wird im SQL-Server ausgeführt. Durch Setzen von sinnvollen Bedingungen, wie Zeiträume, lassen sich die Datensätze, die über das Netzwerk transportiert werden müssen, stark reduzieren.
Sortierung festlegen #
Die Daten können nach jedem Feld sortiert werden. Die Sortierung kann auf- oder absteigend sein. Zusätzlich ist es möglich, mehrstufig zu sortieren.
Wenn Sie sich entschieden haben, die Daten zu sortieren, können Sie im nächsten Dialog die Felder auswählen.
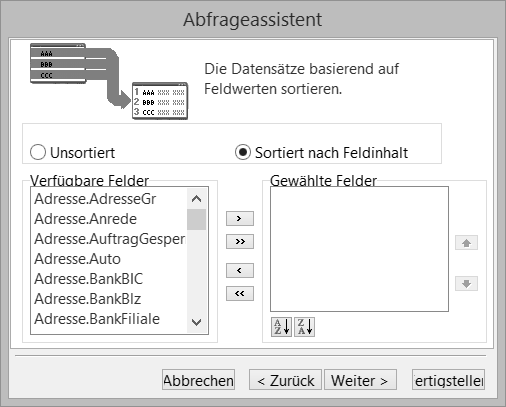
Felder sortieren
Ein Feld wählen Sie durch Doppelklick oder durch Anwählen und Betätigen des rechten Pfeils zwischen den beiden Auswahlboxen. Bei mehrstufiger Sortierung wählen Sie einfach weitere Felder aus. Über die Pfeile am rechten Rand können Sie die Rangfolge bei mehrstufiger Sortierung nachträglich verschieben.
Möchten Sie bestimmte Felder absteigend sortiert haben, so wählen Sie das entsprechende Feld rechts aus und wählen dann die gewünschte Sortierung über eine der beiden Schaltflächen unter der rechten Auswahlbox.
Name der Datenquelle festlegen #
Der Assistent hat nun die Abfragen abgeschlossen. Im letzten Dialog können Sie den Namen der neuen Datenquelle festlegen. Standardmäßig wird hier der Name der ausgewählten Tabelle verwendet.
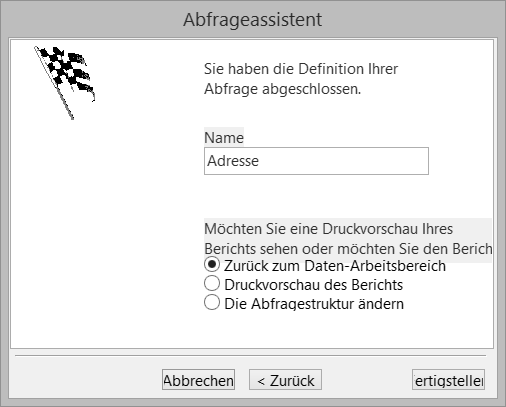
Name wählen
An dieser Stelle können Sie nach Fertigstellung zum Daten-Arbeitsbereich wechseln und die Datenquelle kontrollieren, die Druckvorschau wechseln oder die Abfragestruktur ändern. Bei Änderung der Abfragestruktur wird die Standardeingabe zur Definition der Datenquelle aufgerufen. In der Regel wird man hier die Standardeinstellung übernehmen.
Die Fertige Datenquelle #
Die Datenquelle kann nun im Layout verwendet werden. Sie können die Daten zuvor in einem Browser (=Listendarstellung) kontrollieren. Hierzu rufen Sie das erste Symbol der Datenquelle – das Symbol mit dem weißen Blatt und der Lupe – auf.
Über die anderen Symbole kann die Datenquelle individuell verändert werden. Wurde also im Assistenten eine Option übersehen, so kann dies hier überarbeitet werden.
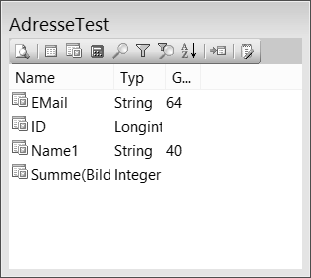
Fertige Datenquelle
Datenquelle verbinden #
Gibt es in Berichten mehrere Datenquellen, so besteht die Möglichkeit, diese zu „verlinken“.
Bei nicht eingebetteten Datenquellen geschieht das im Datenkonfigurator bei der jeweiligen Datenquelle unter dem Punkt „Link“ (Zeichenfolge) in folgender Syntax:
Datenquelle_A:Feld_von_Quelle_B=Feld_von_Quelle_AIm unteren Beispiel befinden wir uns in der Datenquelle pPos (Rechnungspositionen), und das Feld KopfID dieser Datenquelle wird mit dem Feld ID der Datenquelle pKopf (Rechnungskopf) verlinkt.
Bei Berichten mit eingebetteten Datenquellen kann man die Links per Drag&Drop einfügen. Das Beispiel unten würde im Datenkonfigurator folgendem Link in pZE (Zahlungseingänge) entsprechen.
Bei eingebetteten Datenquellen fällt neben dieser komfortablen Methode der Verlinkung auch noch auf, dass man mit einem Doppelklick auf den Link (die Linie die den Link repräsentiert) weitere Einstellungen erreichen kann.
An dieser Stellen kann man einen weiteren Link hinzufügen – das wird selten benötigt –, den bestehenden Link löschen und – das ist das entscheidende – zwischen zwei Eigenschaften des Links wählen.
Verschachtelte Berichte #
Die KopfID einer geleisteten Zahlung entspricht immer der ID der dazugehörigen Rechnung. Das können wir uns zunutze machen indem wir die Datenquellen Rechnungskopf und Zahlungseingänge verlinken. Was wir brauchen ist ein Link von der KopfID der Zahlungseingänge auf die ID der Rechnung. Dadurch werden die Zahlungseingänge sozusagen mit der Rechnung verkoppelt, d.h. wenn im Detailbereich eine neue Rechnung gedruckt wird, dann ändert sich natürlich die ID, und damit die KopfID der Zahlungseingänge (ist ja verlinkt) und somit werden nur Zahlungseingänge der aktuellen Rechnung gelistet.